

Fenghuan EA uses machine learning clustering principles to analyze data, identifying groups of objects or events with similar characteristics or relationships. It uncovers hidden patterns and classifies objects by similarity, helping to identify cause-and-effect relationships.
Attention!!! Please read carefully the rules for installing the advisor, and install it correctly. Before publishing, we check everything and publish only those advisors that work on our accounts !!! At least at the time of this article’s publication. Also, please note that the name of the adviser has been changed, you can find the original name of the adviser in our telegram channel https://t.me/FX_VIP/2527
| Developer price | |
| Terminal | MT4 |
| Currency pair | EURUSD, XAUUSD |
| Timeframe | M30 |
| Money management | At least 100 currency units for each pair |
| Recommended brokers | IC Markets |
| For advisor recommended to use VPS 24/5 | vps24hour – Excellent inexpensive VPS for $3 per month you can use up to 3 terminals!!! |
1. The model is trained for each cluster, the cluster is selected based on the results of trading on the test.
2. Clusters are used to filter out bad trades. First, the sample is grouped into n clusters, then for each cluster the incorrectly predicted examples are counted and marked as bad. Because the average of the bad examples over several cross-training folds is used, the averages for each cluster are different.
3. After filtering out all bad trades, the clusters are memorized and discarded, using only profitable trades, only profitable trades are genenerated into our trading system.

We are interested in the possibility of clustering financial time series both from the point of view of defining market regimes, and from the point of view of matching and defining heterogeneous tritment effect. We begin by attempting to cluster market regimes.The following code performs meta-learning model training and subsequent training of the final model and meta-model based on the clustering results, which is based on the volatility of the financial data:
")
The training function of the final models is as follows:


The K-means algorithm is a data clustering method widely utilized across various sectors, including retail. It enables the grouping of data into clusters based on similarities. In the retail industry, employing K-means for store clustering enhances sales, optimizes product assortments, and facilitates informed decisions on pricing and marketing strategies. For instance, analyzing customer groups based on their behavior towards discounted items or determining optimal delivery routes for logistics improvement. Additionally, K-means aids in customer segmentation, identifying client needs, managing assortments, and enhancing customer retention levels. This algorithm proves instrumental in enhancing operational efficiency and driving strategic decision-making in the retail landscape


The Affinity Propagation algorithm is a data clustering method that does not require a predefined number of clusters. It automatically identifies cluster centers and assigns data points to clusters based on their similarities. This algorithm is particularly useful when the number of clusters is unknown or when data does not conform to traditional cluster shapes. Affinity Propagation stands out by taking input on similarities between pairs of data points and considering all data points as potential exemplars simultaneously. Interaction between data points is achieved through exchanging real-valued messages until a set of high-quality exemplars and corresponding clusters is determined. The algorithm requires two sets of input: similarities between data points and preferences of each data point to be an exemplar. Affinity Propagation can handle clusters of various shapes and sizes and finds applications in diverse fields such as image segmentation, customer segmentation, and gene expression analysis. Despite its computational demands, this algorithm remains a valuable tool for clustering data with complex relationships and nonlinear structures.


Mean Shift is a non-parametric clustering algorithm that does not require a predefined number of clusters. It iteratively adjusts data points’ positions to maximize local density, converging towards modes or peaks in the data distribution to form clusters of varying shapes and sizes. This algorithm is particularly suitable for datasets with unknown cluster characteristics and is adept at identifying clusters with complex structures. Mean Shift is widely used in various fields, including computer vision for image segmentation, object detection, and tracking. It is known for its ability to automatically determine the number of segments in an image during processing, making it a versatile and powerful tool in data analysis and image processing

Spectral Clustering is a data clustering method that utilizes the eigenvectors of the similarity matrix to partition a dataset into clusters. The key idea is to use the eigenvectors of the Laplacian matrix of a graph to represent the data and identify clusters using algorithms like K-Means. Spectral Clustering can handle large datasets, work with nonlinearly separable data, and be robust to noise and outliers. However, it can be computationally intensive and requires proper parameter selection, such as the number of clusters and the similarity matrix. Spectral Clustering is a powerful technique for clustering data with complex structures and is commonly used in various fields for tasks like image segmentation, community detection in social networks, and dimensionality reduction.

HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) is a clustering algorithm that extends DBSCAN by converting it into a hierarchical clustering algorithm. It is designed to handle noisy data and identify clusters of varying densities. HDBSCAN works by building a hierarchical tree of clusters, where each cluster is represented by a density peak. The algorithm then extracts a flat clustering from this tree based on the stability of the clusters. This approach allows HDBSCAN to handle clusters of different shapes, sizes, and densities, making it a powerful tool for data analysis.
Settings:
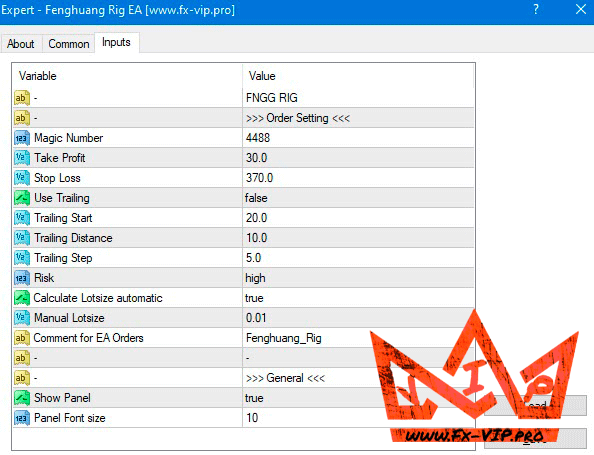
Functionality tested, in build 1440 working.
Reminder: As with every trading system, always remember that forex trading can be risky. Don’t trade with money that you can not afford to lose. It is always best to test EA’s first on demo accounts, or live accounts running low lotsize. You can always increase risk later!
Recommend, in order not to miss important news and updates on the site, subscribe to our telegram channel https://t.me/Fx_VIP
DOWNLOAD EA Fenghuan




